-Better software for Better research-
Introduction to the FAIR2 for Research Software training Programme
Useful Information:
This talk is recorded.
You can follow the slides ➡️➡️
Slides are available freely on github.
You can interupt me at any moment if you have a question.
Every blue text is a hyperlink.

Who am I?
Name : Romain Thomas
Role : Head of Research Software Engineering
Previously : Staff Astronomer and Software Project manager at the Very Large Telescope (Chile)
Released/Published a few modules/software:

Who are we? The teams behind the programme
Research Software Engineering
![]()
The Research Software Engineering team is composed of 13 members and collaborates with researchers across the University in building research software. Areas of expertise within the group include: general software development, code optimisation and performance, reproducibility, GPU computing and Deep Learning, High Performance Computing, training, etc…
Who are we? The teams behind the programme
Data Analytics Service
![]()
The Data Analytics Service (IT Services) supports research excellence at the University of Sheffield by bridging technical and analytical gaps through consultation, delivering training, and long-term collaboration with research teams. DAS supports researchers with reproducible data analysis, data visualisation, data engineering, machine learning, statistics, big data, research software, web design, and much more.
Who are we? The teams behind the programme
Library’s Scholarly Communications
![]()
The Library’s Scholarly Communications Team provides specialist services to support researchers at the University of Sheffield. They offer guidance on making your research outputs open access, and give support on good practice in research data management, copyright and licensing as well as open research more broadly.
This is our second year!
During our first delivery we have seen ~250 registrations to our training programme from all Faculties at the university. 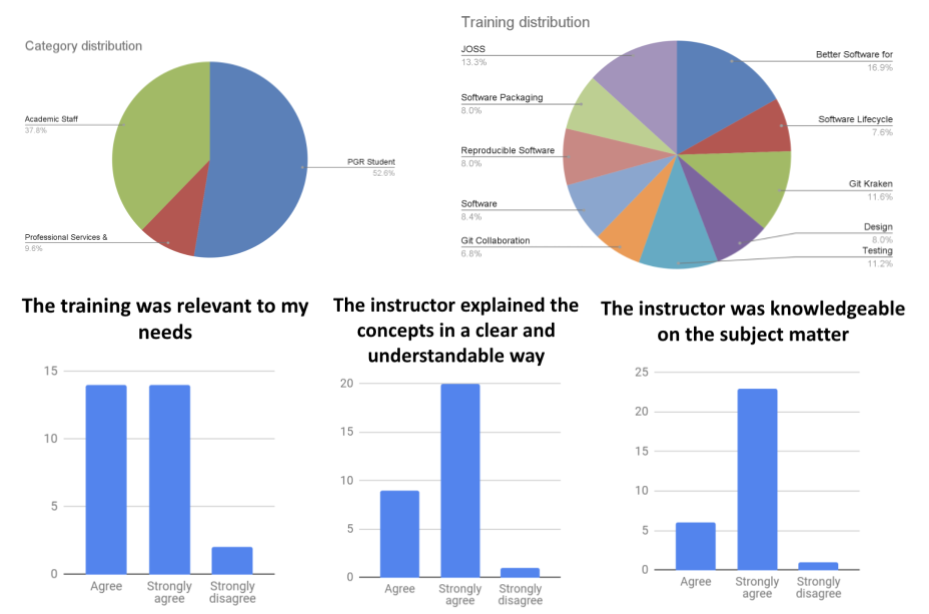
Research is a continuous process
“The succession of researchers is comparable to a single person who learns indefinitely.
Pascal, Pensee, French Mathematician, Physicist, inventor, philosopher and theologian [1623-1662] 
- That’s very old….
- But still very valid…
- And becomes much more difficult with the
complexity of modern research
And that can be trusted…
- Research relies on the ability to trust what has been done before.
- This means that a result has been tested, verified and could be reproduced ➡️➡️
- Tools and methods used for a particular result are known and shared…
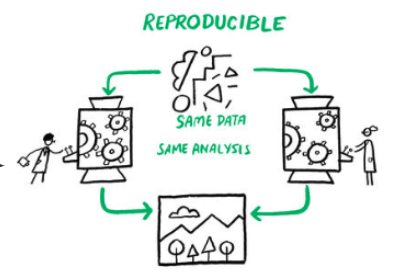 The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
What if a generation of researchers stop doing this?
- Tools and methods used for a particular results are NOT known and shared…
- This means that a result can NOT be tested and verified and can NOT be reproduced.
- ➡️ It is harder to trust research
The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
Are we far from reaching this situation?
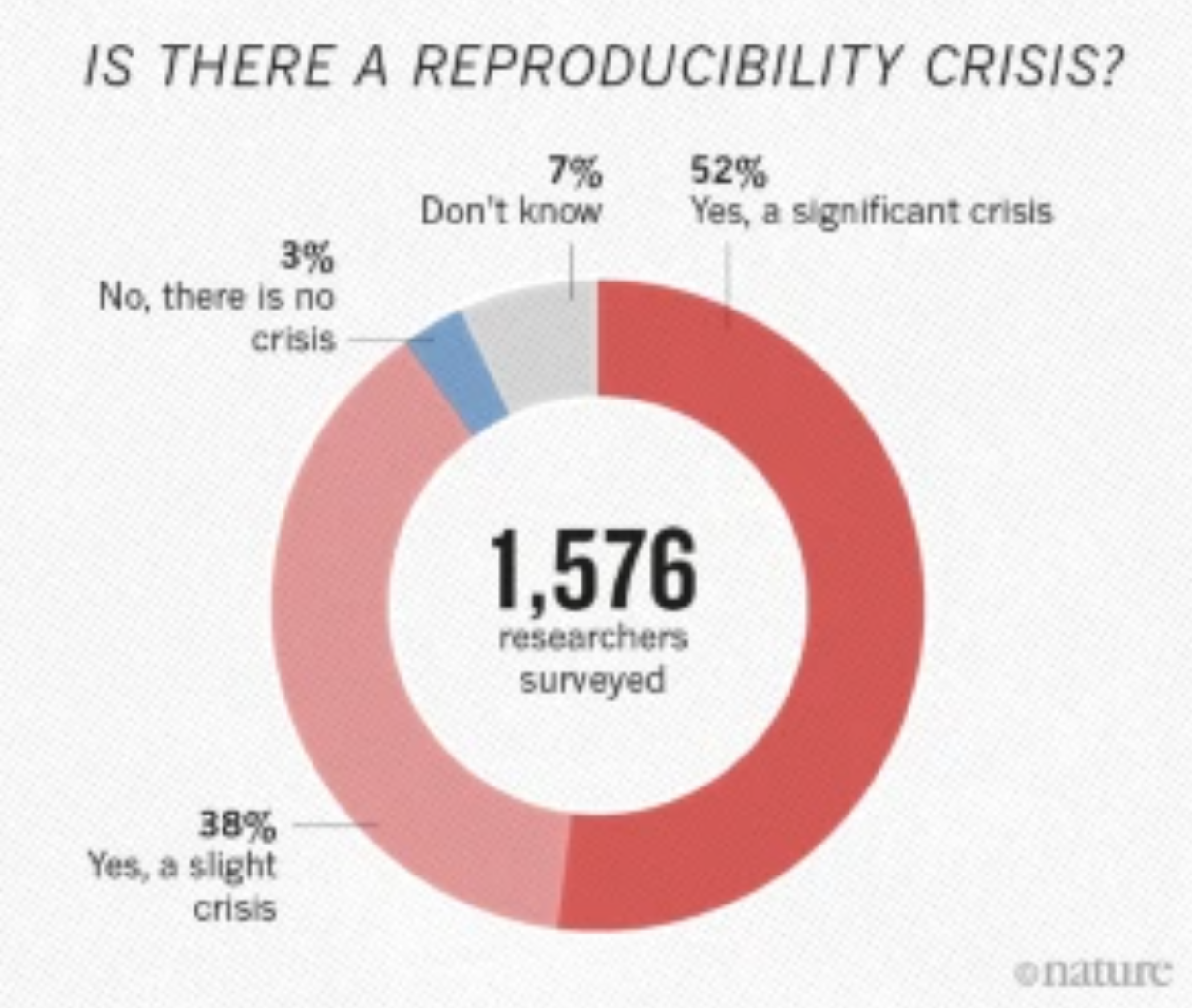
- 90% said there is a crisis!
- More than 70% of researchers have tried and failed to reproduce another scientist’s experiments…
- And more than half have failed to reproduce their own experiments.

Let’s improve!

The FAIR principles
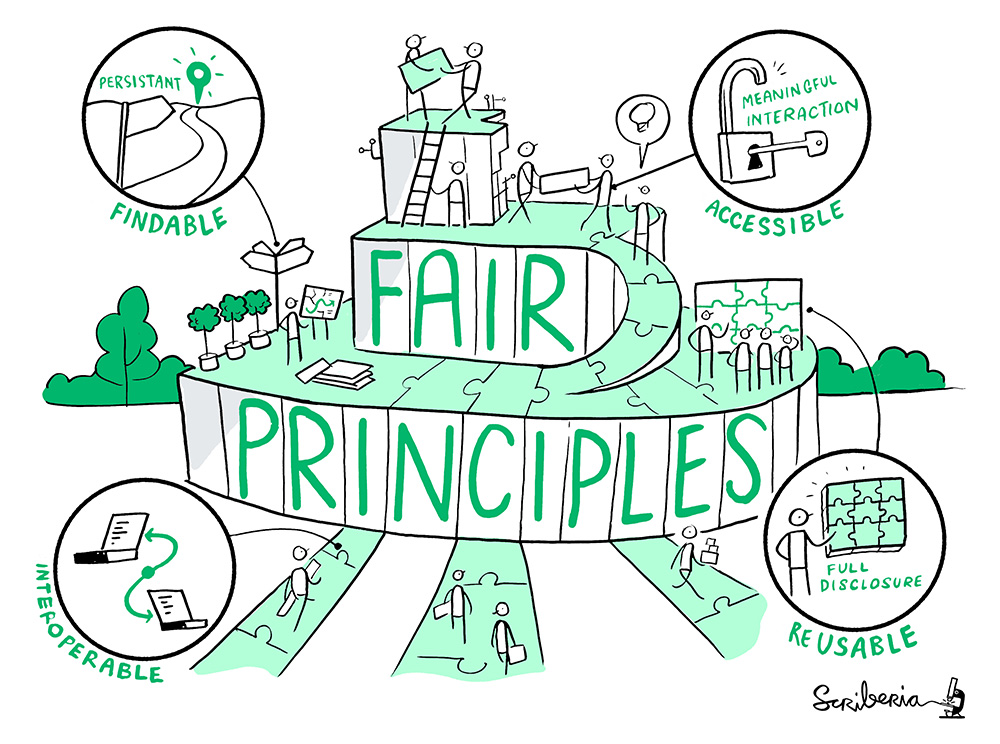
The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence. DOI: 10.5281/zenodo.3332807
A guideline for those wishing to enhance the reusability of their data holdings
–Wilkinson et al. (2016)–
Barriers to FAIR24RS
- fear of prejudice
- important to create a positive culture
- fear of ‘theft’
- licensing and citation
- technical and time barriers
- support is available!
- only need to learn once
- non-commercialisable?
- open source and commercialisation are compatible
- greater impact through open source

Benefits of FAIR24RS
- Accelerate research
- Increase transparency of research
- Increase visibility, citation, reputation and impact
- Reduce duplication of effort
How to be FAIR?

FAIR4RS: Think about how you are coding…
- Where possible, make your code modular.
- Comment your code to make it as clear as possible.
- Create and provide tests that others can use.
- Follow code standards



FAIR4RS: Be open even inside the code!
- Where possible and applicable, outputs (even between pieces of code) should use open and accessible data formats, which will help if other researchers only wish to use part of your code.
- But do NOT reinvent the wheel! In some research fields data format are standardized ➡️ if you want people to use your code, use [your] community standards!

FAIR4RS: Version your code!
- Using version control software platform such as Github/GitLab allows you to keep track of the changes you make to your code
- You can release version of your software/code/scripts directly from Github. While it should not be used a long term storage place, It gives a place where your code can be downloaded and where people can contribute.

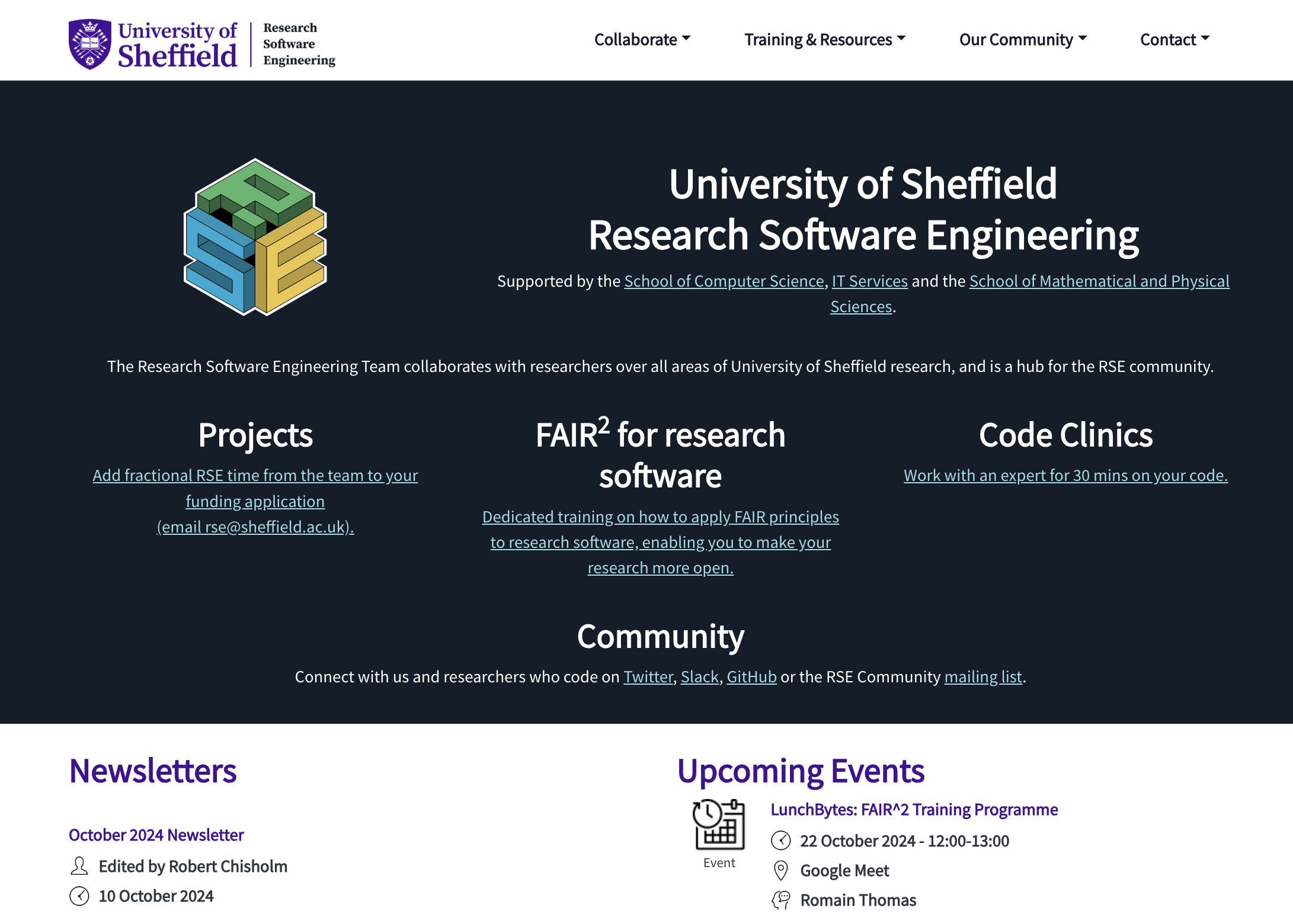
FAIR4RS: Document your code!
A little poem from A beginner’s guide to writing documentation:
- If people don’t know why your project exists, they won’t use it.
- If people can’t figure out how to install your code, they won’t use it.
- If people can’t figure out how to use your code, they won’t use it.
In practice, Github can host documentation as website (and it is very easy to do!) ➡️➡️
FAIR4RS: Licence your code!
You need to tell people how they can re-use your code.
- GPLv3 The GNU General Public License: a free, copyleft license for software and other kinds of works. It is intended to guarantee your freedom to share and change all versions of a software to make sure it remains free software for all its users
- MIT licence: is a permissive free software license. Without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software,

The licence must be made clear in the code repository and in the documentation.
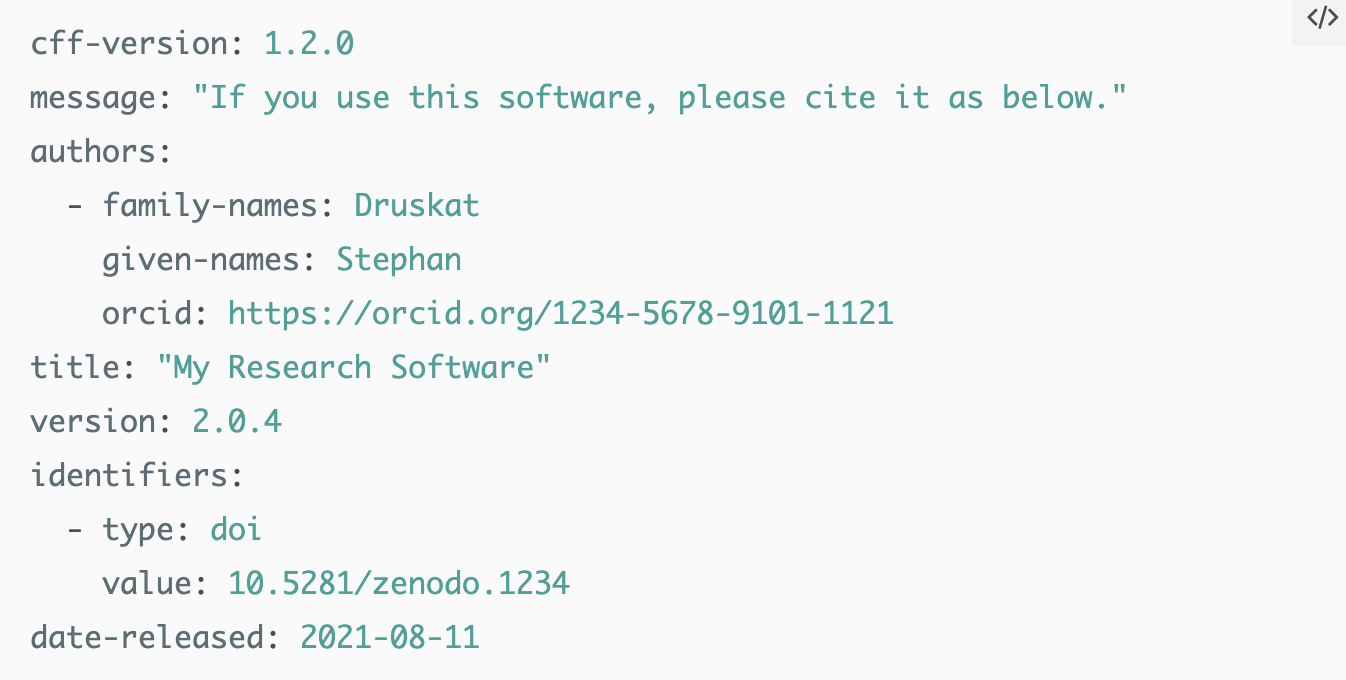
FAIR4RS: Get credit for your work
If people are using your software you should get credit for it.
➡️ state how you want to be credited. You can add it in the documentation and/or create a citation.cff file that you can add with your code (tools. are available to generate them)

FAIR4RS: Share it!
- Create a description of your code with metadata [data about your software].
- Codemeta is a set of keywords used to describe code and how to structure them in a machine readable way
Examples:
- The citation.cff file contains metadata
- Description keywords
- Url to repository, to documentation
- List of contributors and affiliations
- etc…

FAIR4RS: Share it!
In order to ensure that others can access and download your code, and that this access remains permanent over time, you should deposit your code in a repository. Two types:
- General purpose
- Domain Specific
Choose what makes more sense for you project!
FAIR4RS: Share it!
In order to ensure that others can access and download your code, and that this access remains permanent over time, you should deposit your code in a repository. Two types:
- General purpose
- Domain Specific
Choose what makes more sense for you project!

Numerous repositories give your content a DOI [Digital Object Identifier] It means it can be cited in publication and other communications in order to open up your research to others and invite collaboration, as well as ensuring a constant link to your code.
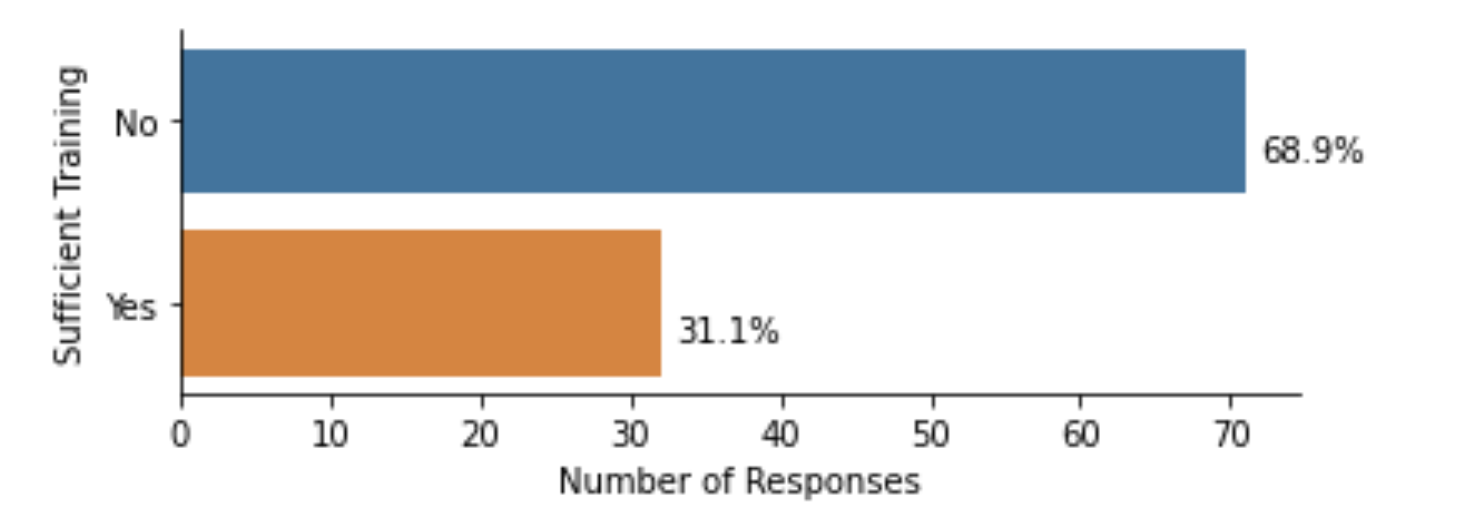
Lack of skills for developing software
Do you feel that you have received sufficient training to develop reliable software?
Bob Turner & Paul Richmond, UoS, RSE team, github.com/RSE-Sheffield/sssurvey.
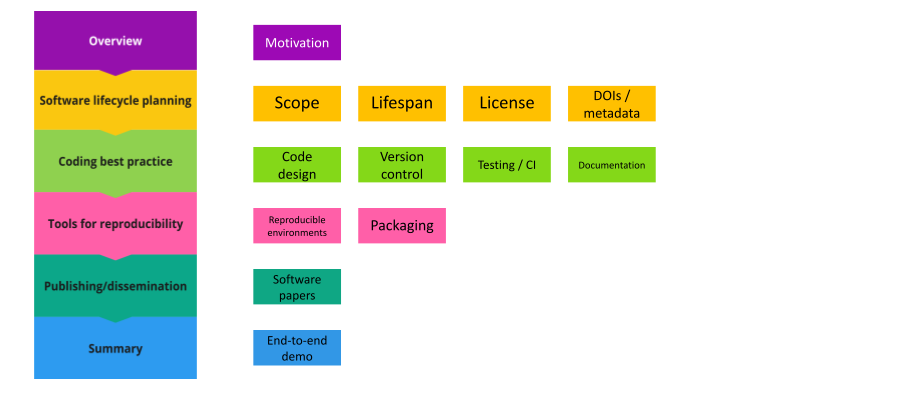
The FAIR24RS Programme: Overview
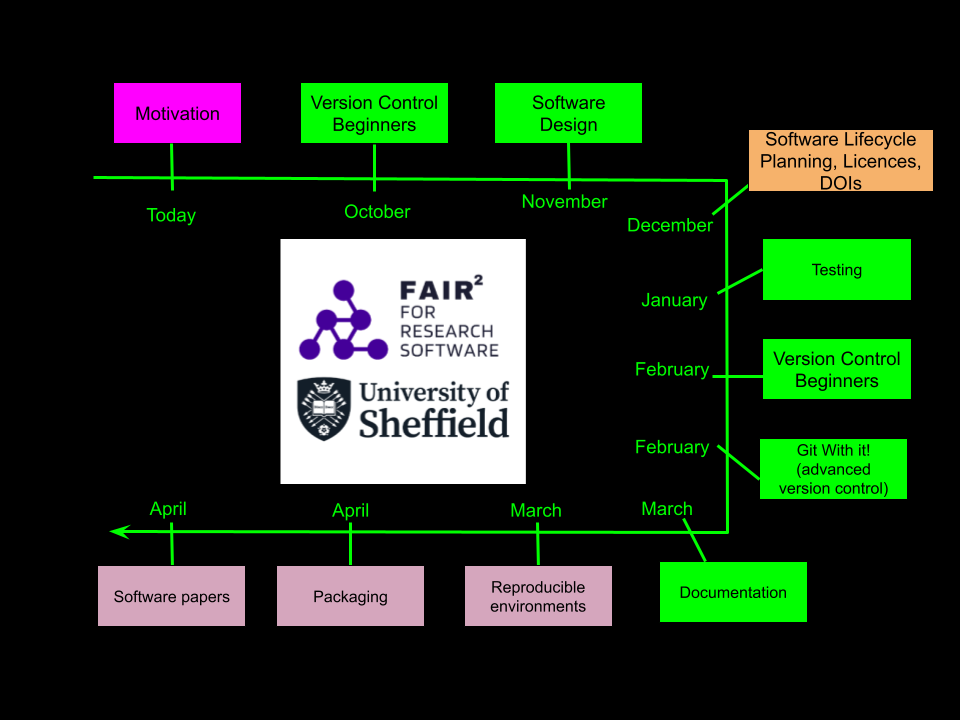
The FAIR24RS Programme: Timeline
The FAIR24RS Programme: Material and dependencies
All materials are designed using the same structure (Software Carpentry workbench) and are freely accessible on Github.
You can pick-and-choose the lecture you will follow based on the skills you already have. Each lecture comes with a set of prerequisities that are clearly identified.
A feedback form will be provided after each lecture.
the fair24rs programme: important notes
- Training are all Free of charge.
- BUT! they all need registration and in-person sessions have limited places!
- They will all be available on mydevelopment platform. The first 3 sessions are already open for registration:
- Git/Github zero to Hero - Oct 28th & Nov 4th
- Code Design - Nov 26th & Dec 3rd
- Software Management plan - Dec 12th
- January onward sessions will be available for booking around December.
- Direct links are also available on the RSE website:

RSE website

Contacts:
- Tamora James -RSE and FAIR24RS Programme Manager -(t.d.james@sheffield.ac.uk)
- Romain Thomas -Head of RSE-(romain.thomas@sheffield.ac.uk)
Thank you!

Help us improve!
Scan to give your feedback!